Where we ended up last time is that we have a heurisic model that gives us the following metrics:
| AUC/ROC | Brier Score |
| 0.79 | 0.12 |
What we'd like to do now, is to try and find an ML method that can do better than this, but first off. Where do we even start?
So many models, so little compute
The first question is to identify what kind of problem we're actually solving. We're not labelling drivers as podium or not podium, we're predicting a probability for each driver. That's a classification framing, and it drives every decision below.
Neural nets are off the table. They're exceptional at finding complex non-linear patterns, but they're incredibly data hungry, millions of rows is a reasonable baseline for stable training. At 26,000 rows we'd be fighting overfitting from the start, with no guarantee the added complexity pays off.
That leaves tree-based models, which are well suited to structured tabular data at this scale. They handle mixed feature types, numeric rolling stats, categorical constructor IDs require minimal preprocessing, and produce well-calibrated probability outputs via a binary objective.
Within that family, we're choosing LightGBM over XGBoost. XGBoost grows trees level-wise, splitting every node at a given depth before going deeper. That makes it more conservative, more resilient to outliers, and better suited to very small or heavily imbalanced datasets. But, it's slower because it pays attention to everything exhaustively. LightGBM grows leaf-wise, greedily splitting whichever leaf offers the highest loss reduction. That makes it faster, which matters here because we'll be iterating heavily on feature engineering.

One cavet is that small datasets are actually more prone to overfitting with LightGBM, not less. Leaf-wise growth is aggressive, and with too few rows it can effectively memorise the training data. However, our dataset sits in a reasonable middle ground with thousands of rows, not hundreds. We can mitigate the remaining risk with regularisation parameters and cross-validation.
If the dataset were truly tiny, XGBoost would be the safer choice. But for our purposes, LightGBM should be great.
Lightly trying LightGBM
So firstly, we load in all of our data and merge it all across so that we have all of the useful features together. But, we intentionally do not merge in any of the qualifying data. Why? For the reasons that we talked about before, we won't have access to it before so we shouldn't be training out model on it either.
So we load it all in, create a new feature called "podium finish" and limit it to only the pre-2026
full_race_data_df = pd.merge(
left=res_df[["resultId", "raceId","driverId", "constructorId", "position", "statusId"]],
right=race_df[["raceId","year","round","circuitId","name","date"]],
on="raceId"
)
full_race_data_df = pd.merge(
left=full_race_data_df,
right=drivers_df[["driverId","dob","nationality"]],
on="driverId"
)
full_race_data_df["podiumFinish"] = (full_race_data_df["position"] <= 3).astype(int)
training_race_data_df = full_race_data_df[full_race_data_df["year"] < 2025].copy()Okay great! So what's next? We select which features we want to plug into the lightGBM model and also identify which features are categorical, this is important as we need to pass this information to lightGBM because categories get split in a different way e.g. red isn't "better" than blue just because one happens to be encoded as 1 and the other as 2
features = ["driverId", "constructorId", "circuitId", "year", "round"]
cat_features = ["driverId", "constructorId", "circuitId"]
for col in cat_features:
full_race_data_df[col] = full_race_data_df[col].astype("category")
X = full_race_data_df[features]
y = full_race_data_df["podiumFinish"]Finally, we want a validation set as well so we leave out 2023 as the validation set because it's time series data we can't randomly split it as we'll leak data through
train_mask = full_race_data_df["year"] <= 2022
val_mask = full_race_data_df["year"] >= 2023
X_train, y_train = X[train_mask], y[train_mask]
X_val, y_val = X[val_mask], y[val_mask]It's the data police, show us your hands!

Okay, a brief interruption. Before we go any further it's really important that we validate our data. Why? Because bad data in will give meaningless results out. We did a little bit of this during the initial EDA with some null checks, counts, and a distribution here and there, but it's much better to have a proper tool for this in place.
This becomes even more important later on when we start pulling in live data via the API to make predictions on races outside this dataset. Imagine everything is fine, and then one day the model's effectiveness collapses. You spend hours debugging only to find out the API pulled back garbage and you trained on that. Getting this in place now means we catch those issues before they become a problem.
Great Expectations is genuinely powerful, but it's designed for enterprise pipelines with heavier infrastructure like Data Contexts, checkpoints, and JSON expectation suites. None of that is useful here. Instead we'll use Pandera, a lightweight library that lets us define validation schemas directly on our DataFrames as Python classes.
class RaceResultSchema(pa.DataFrameModel):
year: int = pa.Field(ge=1990)
raceId: int = pa.Field(gt=0)
driverId: int = pa.Field(gt=0)
constructorId: int = pa.Field(gt=0)
circuitId: int = pa.Field(gt=0)
statusId: int = pa.Field(gt=0)
round: int = pa.Field(gt=0, le=24)
date: DateTime = pa.Field(ge=pd.Timestamp('1990-01-01'))
dob: DateTime = pa.Field(gt=pd.Timestamp('1950-01-01'), lt=pd.Timestamp('2010-01-01'))
nationality: str
name: str
position: float = pa.Field(lt=40, ge=1, nullable=True) # DNFs are Null
podiumFinish: int = pa.Field(isin=[1,0])
# Only one driver should appear per race
class Config:
unique = ["raceId", "driverId"]One thing worth calling out is that this validation must run after filtering to 1990 and beyond. Pre-1990 F1 data has different recording standards and a lot of structural noise that isn't useful in a predictive context, and it will fail the schema by design.
We wrap the .validate() call in a try/except so failures print cleanly rather than exploding with a stack trace. In a production pipeline you'd want this to hard stop, because a schema failure indicates a real data problem upstream and nothing downstream should be trusted until it's resolved. Here, we just want visibility.
It passes cleanly, which means we can move into training with confidence that the data going into the model is what we think it is.
Phew okay, now we can train a model
Finally, we train our LightGBM model. We use the following parameters:
| Parameter | Value | Notes |
|---|---|---|
| objective | "binary" | Binary classification — did they podium or not? |
| n_estimators | 500 | Number of trees to fit. Default is 100, we go higher to see how it performs and can tune down later. |
| learning_rate | 0.05 | Slightly slower than the default of 0.1 — more conservative to start. |
| num_leaves | 31 | Maximum number of leaves in a single tree. The default, but nice to be explicit. |
| min_child_samples | 20 | Minimum samples required in a leaf. Acts as regularisation to prevent over-splitting. |
| verbose | -1 | Silences training output. |
So, how did we do?
There's good news and bad news, technically... according to our metrics. We do okay!
| AUC/ROC | Brier Score |
| AUC: 0.8190 (baseline: 0.79) | Brier: 0.1204 (baseline: 0.12) |
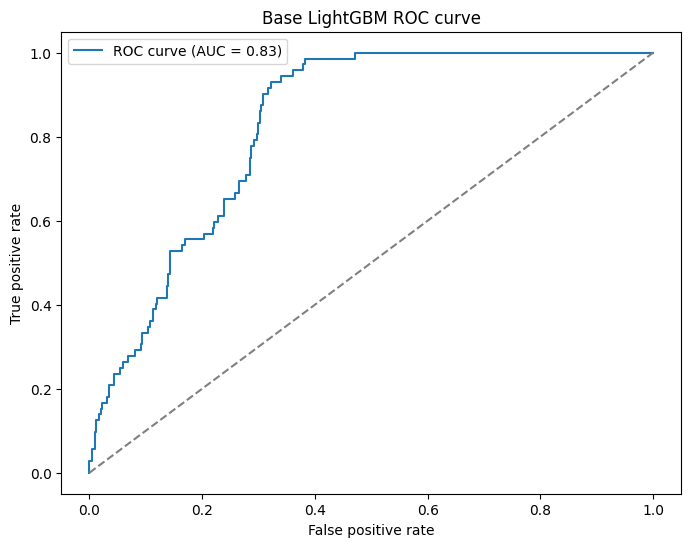
But we start to see problems when we dig a little deeper. If we look at the feature importance graph that LightGBM gives us out of the box, something immediately stands out.
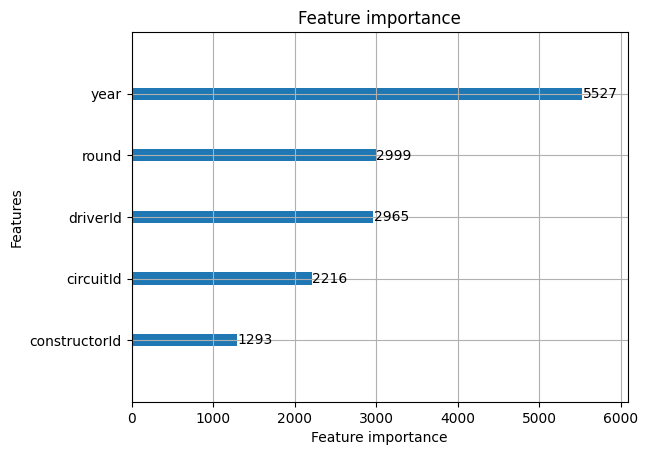
Feature importance tells us how significantly each feature contributed to splitting the data in a meaningful way during training. The problem is that year is by far the dominant feature. We'd expect constructorId to rank much higher as it carries more information about the car, the engineering team, the budget. Instead, the model is essentially learning "in year X, constructor Y tends to win" and leaning on that pattern almost exclusively. Constructor identity is being sidelined entirely.
This is a methodological problem even if the headline metrics look reasonable. A model that works for the wrong reasons is still a model we shouldn't trust. Constructor dominance cycles are real, however, they're not a useful predictive feature for future seasons. Our model has no way of knowing that a new regulation era might completely reshuffle the order.
Confidence issues
There's one more important diagnostic to look at which is the calibration curve. This plots our predicted probability of a podium against the actual observed rate. A well calibrated model should follow the diagonal closely. Ours... doesn't.
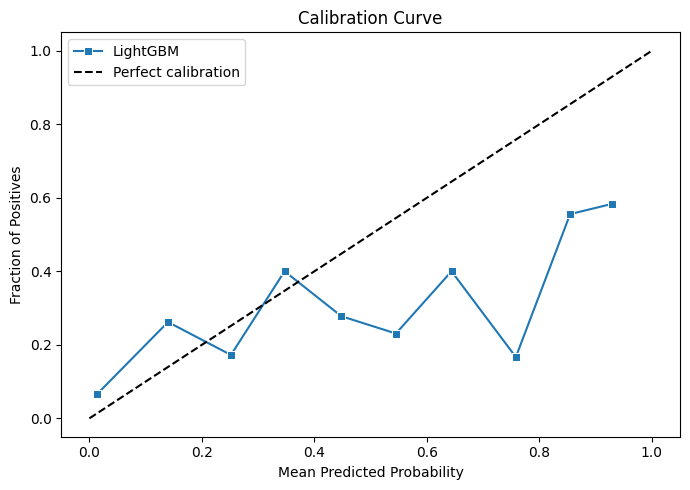
The curve bows significantly below the diagonal in the middle range. This means the model is very underconfident in its mid-range predictions. It's hedging where it should be committing. We're not terrible at identifying who will podium, but we're quite bad at saying how likely that is, which matters a lot for a probability model.
The prediction distribution makes this even clearer.
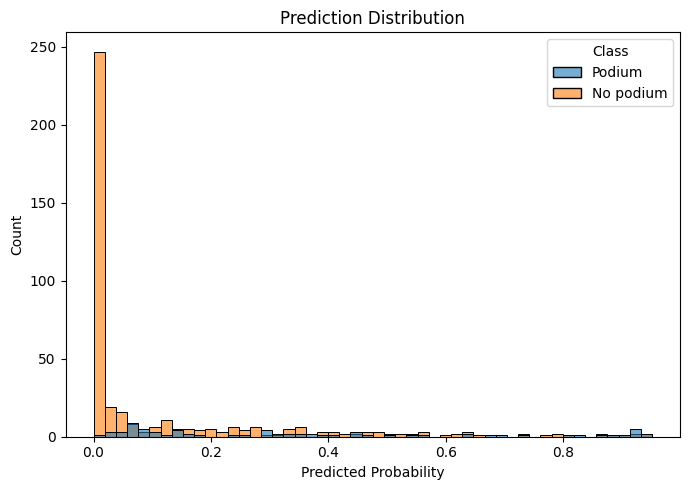
The vast majority of predictions are piled at the low-probability end. The model is defaulting to "probably not a podium" for almost everyone, which works out often enough given our class imbalance, but it means the two distributions are barely separated. The model isn't finding features that meaningfully distinguish podium finishers from the field.
Testing time.
So the feature importance and calibration diagnostics tell a concerning story. But, do they actually show up in the test results? Let's find out.
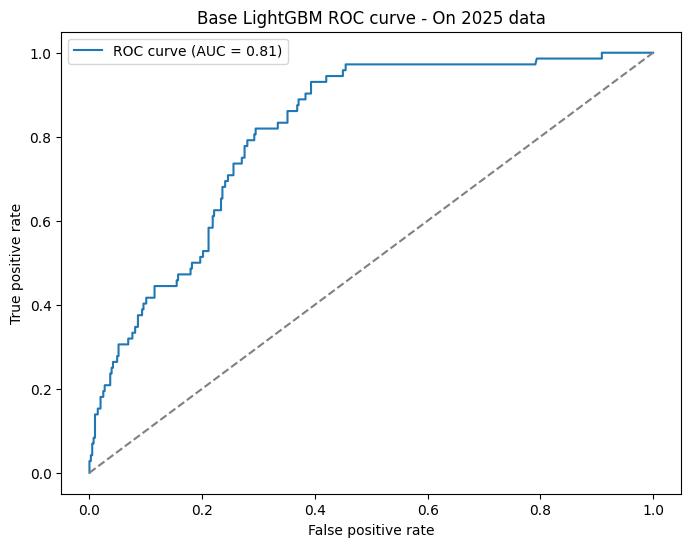
| AUC/ROC | Brier Score |
| 0.8116 (baseline: 0.79) | 0.1215 (baseline: 0.12) |
Honestly? Better than expected. The model generalises to 2025 without collapsing, which is a pleasant surprise given what the feature importance graph was suggesting. But this is where we need to be careful a good number on a flawed model is not the same as a good model. The year feature is still doing most of the heavy lifting, and we have no guarantee that pattern holds into future seasons, especially at regulation boundaries. We got away with it in 2025, but we're not building something we can trust yet.
What did we learn & where do we go now?
Even a flawed baseline teaches us a lot. Here's what we've learned from this round:
- Year is acting as a proxy for constructor dominance, masking whether constructorId is contributing any signal of its own
- The model's calibration is poor. It knows roughly who will podium but not how confident to be about it
- The rolling podium rate we built for the heuristic baseline likely has more genuine predictive signal than anything in this model
- Constructor should carry far more importance, but the current feature set doesn't give the model a way to see that
So, what are we going to do next?
| Next Step | Why |
|---|---|
| Rethink year as a feature | It's masking constructor signal and won't generalise across regulation changes. We'll explore replacing it with a coarser regulation era feature that captures the useful part without the temporal leakage |
| Set up MLFlow for experiment tracking | We're about to iterate heavily on features, we need to track exactly what changes led to what results, or we're flying blind |
| Engineer new features | Rolling podium rate already showed strong predictive power. We'll bring that in, and explore circuit characteristics, driver age, and constructor-level form signals |
| Hyperparameter tuning | No point tuning until the features are right. But, once they are, tuning should compound the gains. Key items include scale_pos_weight to address class imbalance and walk-forward cross-validation for more robust evaluation |
Next time...
We'll set up MLFlow to track how our model evolves as we engineer new features, address the class imbalance problem, and move to a more rigorous validation approach.
